After trying to organize my daily life, I have finally found a good opportunity to work on this.
Before I start I would like to say thanks to my colleague Michael van der Merwe. He had a challenge and I got the opportunity to collaborate with someone that helped me a lot when I started fishing in the early Classic FDM times. If you come from old Upstream/FDM, I'm sure you know this guy.
Before we dive into this fuzzy concept I think I should briefly describe what I will be showing today so we are all in the same page.
As you may know, HFM allows adding a text description to any valid cell.

This description is known as Cell Text and, luckily, FDMEE can load it by attaching to data lines something called Memo Item.
However, out of the box, FDMEE only allows adding memo items manually once data has been imported. Today we will focus on how to import memo items from the source (file or any other) and loading them as cell texts into HFM.
However, out of the box, FDMEE only allows adding memo items manually once data has been imported. Today we will focus on how to import memo items from the source (file or any other) and loading them as cell texts into HFM.
That's the goal :-)
Memo Items: attaching text descriptions to FDMEE data
I'm sure you have asked yourself (at least once) what is that post-it icon in the very first column on your Data Load Workbench grid. Have you ever clicked in the "--" link of any data line? If you do so, you will see a new window popping up. Welcome to memo items :-)

As we have already shown in this blog, all is stored in the database. So the best we know how it is stored, the best positioned we are to control it. It sounds interesting, doesn't it?
Lets' then have a look to what happened in my FDMEE database when I just clicked Add (all db screenshots are for MSSQL):

Picture above is self explanatory but I would like to highlight some key points:
- Memo items are stored in table TDATAMEMOITEMS
- Memo items and data lines are linked through the column STATICDATAKEY
- I don't know why but column MEMOITEMKEY reuses sequence used by Data Load Rules (I can see potential issues when adding memo items and data load rules at the same time. Maybe not a common case but something that can really happen)
Once that we have added our memo item, we need to type a name and a description. Optionally we can attach up to 10 documents. At this point you must know that current functionality does not support loading of attached documents to the HFM cell text. In any case, you can use this feature in FDMEE in case you want to attach any file to data lines (ex: invoices)


Are you curious? Of course you are. So if you have a look to the columns where attached documents are stored, you won't see any path, just an identifier. To what? As many other files in FDMEE, the information for attached documents is stored in table TDATAARCHIVE:

Loading Memo Items as Cell Texts
To show this functionality I don't need to do any magic, just to enable one target option and click Export.
In this case, I will enable Cell Text loading at data load rule level. Remember that we can override global target application options at data load rule level if needed. When you see the option value is yellow-cream highlighted, then the global option is being overridden:

Now click Export, get all the gold fishes and have a look to your HFM data. There it is, a non really well formatted cell text has been loaded from FDMEE.

Note: HFM allows having multiple cell texts assigned to the same data intersection (Enhanced Cell Text). This can be done by using different Cell Text Labels. Unfortunately FDMEE is limited in this way as it only loads cell texts to [Default] label.
If you try to have multiple memo items to the same data intersection and you export them as cell texts, you will something like this:

Therefore if you have multiple labels and load through FDMEE, then you need to follow another approach. I will not cover this today but as a tip you should know that you can load cell texts by having a section in your DAT file labeled as !Description. In this picture taken from HFM documentation you can see syntax for enhanced cell texts:

If a load using an append mode is run and new cell text is added to an intersection that already has cell text, the old cell text is replaced by the new cell text and not appended.
How are Cell Texts actually loaded?
Cell texts are loaded through the HFM adapter API. From 11.1.2.4 the adapter scripts are available in Jython so if you open script HFM_LOAD.py you will see a function to load cell texts:

Have a look to the entire script and you will better understand how it works. If you are not happy with how the cell text has been formatted (author...) then you can change that code in the same script (not supported...)

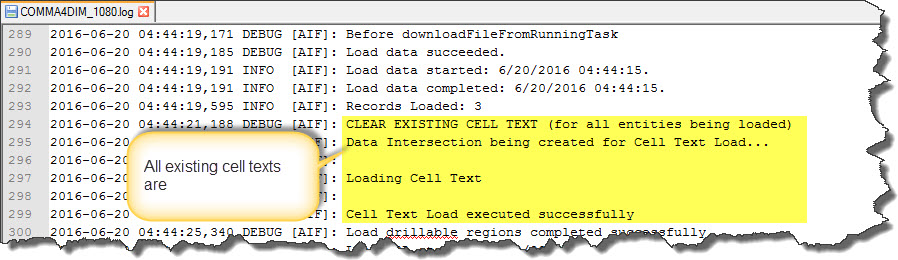
If appropriate log level is configured, the FDMEE process log will show all actions related to cell texts:
Now that we better understand how cell text loading from memo items work, it's time to address common requirement to import memo items from source.
As an example we will import the following delimited file:

If we think about the high level solution, our plan would look as follows:
- Import memo items into FDMEE column (typically attribute or description columns)
- Add memo items to the database
- Use the standard cell text loading option
That sounds like a good plan then, doesn't it?
Importing Memo Items into Description column
We are all familiar with Import Formats, right? Descriptions and Attribute columns are not available when you create the import format but they can be added later by clicking Add button:

After importing data we can show description column to see text imported (View > Columns menu):

Creating the Memo Items Behind the Scenes
I always like to speak about customization from the WHAT-WHERE-HOW standpoint. We already covered the WHAT in step 1. Let's go through the other two.
This is a common customization where you would probably start with the HOW without thinking about the WHERE until last minute, just when you start getting unexpected results :-)
And this is how I'm going to approach it in this blog entry.
The HOW...
We already showed what was happening in the database when new memo item was created. Now it's time to emulate via scripting what FDMEE does when actions are performed in the UI:
We just have to execute an INSERT statement into table TDATAMEMOITEMS. The easiest way is to execute INSERT INTO table VALUES (columns) SELECT columns FROM TABLE



 Memo item has been added but no details are shown. What do you do next? Go to oracle community and ask? Come on, don't be shy and use your SQL skills:
Memo item has been added but no details are shown. What do you do next? Go to oracle community and ask? Come on, don't be shy and use your SQL skills:



What happened now in the database?
 And what about FDMEE?
And what about FDMEE? 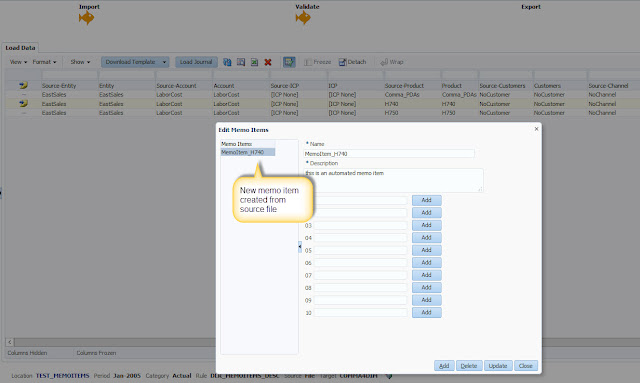
We can now see memo items details as well :-)



2. Update columns HASMEMOITEM and STATICDATAKEY in data table
We need to update DATAKEYs that have memo items assigned:

3. Update sequence value in table AIF_SEQUENCES
The last step is to update the sequence used to generate the MEMOITEMKEY. We can use the number of memo items inserted to update it:

The WHERE ...
One of the first thoughts would be probably to insert new memo items after data has been imported into the FDMEE staging table (TDATASEG_T). This happens in the AftImport event script.
That solution is actually working with no errors but then you get something unexpected when trying to view the memo items in the data load workbench:

Yup, memo item is not in TDATAMEMOITEMS but it was inserted indeed. Ok, my SQL skills were a good starting point but it's time to use my log auditing skills: 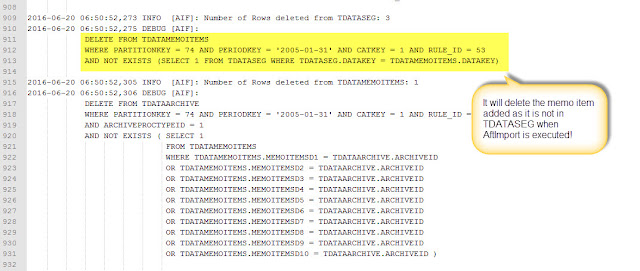

After searching text "TDATAMEMOITEMS" we notice that there is a DELETE statement and...voilà! it is executed after AftImport event script.
Does it mean that the memo item was actually inserted but then deleted because DATAKEY assigned did not exist in TDATASEG yet? Elementary, my dear Watson. Data is copied from TDATASEG_T to TDATASEG table when mappings happen.
Mmm... then going back to the WHERE, we need to perform the SQL operations when data is already in TDATASEG... and that is? AftProcMap event script, simply after mapping happen.
Let's give a try and do some reverse engineering from HFM to see the detailed process:

Our "custom" FDMEE process log shows results of the 3 SQL operations:

What happened now in the database?


We can now see memo items details as well :-)
A known Bug
Something you need to know: Cell Texts and Data Protection are not the best friends. If you are using Data Protection feature, your cell texts will not be protected when loading data in Replace mode. The workaround would be to extract the cell texts before loading data and the loading them back after data has been loaded into HFM.
Update 11/04/2017: Oracle has released a PSE to fix this issue (Patch 25720138)
Update 11/04/2017: Oracle has released a PSE to fix this issue (Patch 25720138)
Loading through Excel TB Templates
I don't want to leave this post without performing one more test. In old Classic FDM times, we could import memo items from Excel TB files. There were two additional metadata tags M1 and M2 to import both memo item text and description:

So I had to test this in FDMEE...unfortunately this is not supported in FDMEE

Conclusions
Cell texts are very useful to keep additional information to your HFM data intersections. This new information may be available in your source data so being able to load it through FDMEE it's definitely a +1
Unlucky we don't have an OOTB functionality to import them but we do have a nice way of extending FDMEE via scripting, and this is what we did!
Enjoy!