Dear colleagues,
I'm back! It has been a hard few months with a lot of work especially at home where the large family has required 200% of my attention.
Many people asked me where I was, although those who know me know that I have not been to the Caribbean :-)
Being said that...
We all know that the Cloud continues to grow with great force and that the role of data integration is fundamental in the architecture of any solution. Some other people including my colleague John Goodwin, have covered many topics of maximum interest. I strongly recommend visiting the different blogs out there although I'm sure you already did it :-)
Today, I come back to show you a solution that we have been implementing in multiple customers. How many of you have had data protection problems in HFM when loading from FDMEE? Do you know all the solutions? I'm not going to cover all of them, but I will be introducing the one that is not fully documented.
As usually, I'm not stating this is the best solution for your requirement. This is just to share with you a new idea that I found very useful for some of my implementations.
The requirement
Let's start with a common question from customers:
When we load HFM data with FDMEE in Replace mode, some accounts are wiped out. Controllers type them, so we need to protect that data. Can we?
Then, you start thinking about different approaches.
- Maybe, we can use Merge mode instead...
- Or Replace by Security...
- FDMEE has built-in functionality for Data Protection...
- Etc.
During your analysis, all options should be evaluated. You need to understand the pros and cons and if they have any impact on existing integration flows.
Let's now take that requirement to another level of complexity. Multiple FDMEE interfaces loading different sets of data for the same HFM sub-cube (Entity, Scenario, Year, and Value). For example:
- ERP data / Supplemental data
- Statutory accounts / IFRS16 accounts
The two examples above have something in common. If you execute the Data Load Rules (same category) with Replace export mode, each DLR will delete the data of the other one. This is how the Replace load method works in HFM so data for the sub-cube is deleted before the new data set is loaded. For example:
- DLR GL_DATA loads actual data in Replace mode for Entity NY, Period Mar-2019
- DLR IFRS16_DATA loads actual data in Replace mode for Entity NY, Period Mar-2019
There can be many different sequences and scenarios but if we focus on the above one, the second execution will delete all the data previously loaded for NY/Mar/2019 (assuming there is no data protection mechanism).
Can I use HFM Data Protection functionality available in FDMEE?
I must admit that I have not been a big fan of Data Protection functionality. The main reason is the way it works, its limitations and the performance impact it can have. Basically, FDMEE (legacy FDM classic too) extracts the data to be protected, and then append to the DAT file that will be loaded.
You can protect, for the sub-cube being loaded, all data being that has specific member name in any of the dimensions of the data intersections, or just all data which has not that member.
Some of the limitations I refer to... you cannot protect multiple dimension members OOTB. Also, protecting data with operator "<>" can derive in FDMEE extracting big volumes of data. Definitely, something to be taken into account.
Therefore, yes, data protection is an option to be evaluated but, in addition to understanding how it works, you need to take it into account in your HFM application design. If you want to protect manual data inputs or different data sets loaded through FDMEE, you may want to consider using an HFM custom dimension (typically Custom4), so the different data sets use different custom dimension members. Each FDMEE interface should protect all data being different than the custom protection member it is loading into. As you can imaging,simply extracting the HFM data requires time and resources. Also,several re-loads can happen depending on our solution design.
BTW, I haven't mentioned Cell Texts but they are included in the data protection process.
What about Merging data instead of Replacing?
If you are thinking that changing your load method can be the solution for your data protection issue, you may be introducing more issues. As we usually say, the cure is worse than the disease. E.g. if you have re-allocations in your data, you might be protecting your data but leaving wrong data in the system as well. There is a well-known custom solution called Smart-Merge but it is not in the scope of this post, so I leave that for your researching.
Replace by Security Load Method and Global Application Users
Let's have a look to a load method different than Merge and Replace. The HFM documentation defines Replace by Security as:
In a nutshell, write and clear the data cells that you access to. This seems to be a good way of protecting data, doesn't it? As you know, FDMEE leverages HFM load methods so Replace by Security is available when exporting data:
So if the user loading data has specific security classes assigned, data being secured will be protected as it will not be cleared. Good, we are on the right path.
Now let's go with users. Let's say the user loading into HFM is an admin user. Restricting access for the admin might no be a good idea. The same applies for non-admin users, assigning security classes for data protection requirements only, might conflict with his role.
What about having specific Shared Services native users for data protection only? That would fit but we don't want everyone using the same user in FDMEE as that is not compatible with other FDMEE featured such us Security by Location.
Luckily, FDMEE has something called Global Application Users. This feature is not new as it was already available in legacy FDM Classic as "Global Logon" option in the target adapter.
In FDMEE, this option is available in the Target Application Options:
Therefore, if we join the two concepts we have global users loading data in Replace by Security mode. Still on the right path. However, this option is only available at target application level. We cannot overwrite it at Data Load Rule level as we can do with other target options:
One target application can only have one global user assigned. This is not good if we want to have multiple global users for multiple data flows.
You may come up with the option to register target applications multiple times which is possible from FDMEE 220. In my opinion, that's not a good idea as most of the FDMEE artifacts are defined at target application level and you would end up duplicating them as well.
This post makes sense when we must find a solution to work around this limitation :-)
Multiple Global Application Users at Data Load Rule level
If we cannot have global users at DLR level OOTB, how can we get them?
Global Users, as many other options, are target application options. Therefore, as we already showed in other blog posts, they are stored at run-time in table
AIF_BAL_RULE_LOAD_PARAMS when the DLR is executed. The technical name for the global user option is
GLOBAL_USER_FOR_APP_ACCESS:
Then, this little hack is easy. We can update the table at run-time based on the logic we define to get the right global user. The script below inserts the global application user for the current DLR only if it does not exist already (this is done in case you want to place the script in different event scripts as shown in section
At which step do we update the global user?)
As you can see, the SQL statement above includes an INSERT/UPDATE combination. Why? Because if you define a global user at Target Application level, there will be an existing line in the table, so we just have to update it. If you don't define it, we just have to insert it. It also avoids issues if you want to use global user in the Validate step to run the intersection check report, and you try to insert it again in the load step (as long as you execute the DLR in one go)
The code I show is valid for Oracle Database but it is similar for SQL Server. You might consider MERGE statement as well. Whatever you implement, the result must be the same :-)
At which step do we update the global user?
The key question is when do we update the global user in our process? The answer depends on your specific requirements, but the table below summarizes the main scenarios:
How do we configure the global users?
It depends on the requirements. For our example, if we need two global users:
- User for GL data: IntegrationUser_INP_FDM
- User for IFRS16 data: IntegrationUser_IFRS16_FDM
We have to perform the following steps:
- Create the security classes in HFM: C4_INP_FDM and C4_IFRS16_FDM
- Activate the security class for Custom4 (App settings in HFM metadata)
- Assign the security classes to the Custom4 members: INP_FDM and IFRS16_FDM
- Assign role Default to the global user so he shows up in the matrix below
- Assign user access to the security classes
Let's see an end-to-end example
We will first show the data protection issue:
- Load GL data first in Replace mode
- Input data manually
- Load IFRS16 data in Replace mode.
To show how the solution works, we will repeat the process but loading IFRS16 data in Replace by Security mode with new global user IntegrationUser_IFRS16_FDM.
- As a starting point, we load the GL data with Replace Mode. Data is loaded to Custom4 member INP_FDM
The HFM data form shows the right data being loaded:
- After loading GL data, we input value 500 manually (Custom4 member INP):
- Finally, we load IFRS data in Replace mode:
As you can see, all data previously loaded has been wiped out after loading IFRS16 data in Replace mode. Therefore, both manual and GL data have not been protected.
Now we have a data protection issue and a solution for it. Once we apply our event script with the code to update the global user at run-time, data looks good after loading in Replace by Security mode. The three values have been protected as expected:
Conclusion
As usually happens for any custom solution, you need to take into account different considerations:
- If you run the data load rule manually, you can select Replace mode as there is no functionality to hide load methods. To avoid that issue, you can always have a BefLoad script which checks the export mode before loading data.
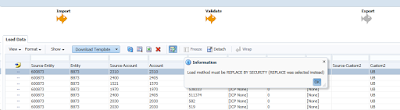
- As you are loading with the global user, that's the user you see in the HFM Audit.
- The solution applies to many different requirements. For example, we had a customer with different security requirements at HFM scenario level. In that solution, we used global users at category level.
- Consider location security. If user A has access to location A, note that the HFM security applied will be the one for the global user and not for user A. Therefore, if user A tries to load data for an entity that he has not access in HFM but the global user has, then data will be loaded for that entity. As a good practice, I usually build a control when locations/data load rules are defined for unique entities. In this way, I prevent users loading data for other entities, especially when they can manipulate the source files :-)
Today, I tried to show you a new solution for data protection that leverages global users, HFM security classes and Replace by Security mode.
I hope you found it useful. Now it is turn for your creativeness.
That's all my folks.



























