
summer is already here :-)
With FDMEE we are saying goodbye to our FDM friends...and today is turn of... varValues!
Do you remember about varValues in FDM Classic? It was that array with all source and target values which could be accessed from mapping scripts (#SCRIPT) in order to create conditional mappings.
You may be familiar with this example:


The drawback of conditional mappings/script mappings was performance. We always tried to avoid them (didn't you?).
So what is a multi-dimension mapping then? its name is self explanatory but if you didn't get it: it's basically a mapping where the target value is defined based on combination of other dimension values. Multi-dimensional mappings are an example of conditional mappings. Here I haven't specified if target value is derived from source or other target dimension values. We will assume both so far.
- Example 1: Target Account is derived from Source ICP and Source Sub-Account Values
- Example 2: Target ICP is derived from Target Account and Source Entity Values
In FDM Classic we had 4 mapping types: Explicit, Between, In, and Like.
In FDMEE we have one additional mapping type to those four: Multi-Dimension Mapping (MD)
MD mappings enable us to define member mapping based on multiple source column values.
So we can now create mappings based on source values in a really easy way by using the GUI. No more scripts needed for this mapping type? Well not really, if you read carefully, "...mapping based on multiple source column values". In current FDMEE version when you want to create a mapping based on target values or combination of source/target values, you still have to use mapping scripts (either #SCRIPT for Jython or #SQL for SQL syntax mappings). If somebody from Oracle is reading this...that would be a great enhancement :-)
How does it look? How do I create them? How do they perform? ... let's try to put some lights on it.
Using the GUI to create a MD mapping
There is a new tab "Multi-Dimension" when you open Data Load Mapping page:

- Target Value: our target dimension member (of the dimension we are defining the mapping for)
- Rule Name: name for our mapping rule. This is key for mapping sequence
- Grid for source dimensions criteria (MD conditions)
- Which criteria can we use to define MD mappings? the other 4 mapping types: Explicit, Between, In, Like

I will create the following MD mapping for Customer dimension:
If Source Entity like West* And Source Product = "Comma_PDAs"
Then Target Customer = "Francisco"
So my MD mapping rule for Customer dimension derives the target customer based on source entity and product columns (dimensions, segments, etc.)


When we save it the new mapping is displayed:

Did you notice new syntax of source value?
ENTITY=[West*] AND UD1=[Comma_PDAs]
What about adding In and Between conditions?

- In: translated to SOURCE_DIMENSION=["comma delimited list"]
- Between: translated to SOURCE_DIMENSION=["IniRange > EndRange"]

Let's run the workflow and see the results:

MD mappings are displayed in mapping details view as other mapping types. By using "View Mappings" option (click amount > View Mappings),administrator and users can track which mappings are applied to any target intersection:

What can we see in the FDMEE Process log? The MD mapping is translated to an UPDATE SQL statement having the conditions as filters:

Using Lookup dimensions in MD mappings
We have already discussed about lookup dimensions in other posts. Basically they are FDMEE dimensions which means only used for FDMEE purposes, not exported, no impact on target application. Typically we use them for mappings and reference. Let's say that we have added a lookup dimension MyLookUp to our target application (Setup Tab > Register > Target Application > Dimension Details Tab > Add):

Note: Data Table Column Name must be a UD dimension greater than our target dimensions. So if my HFM application has 5 Custom dimensions, I can set this value for my lookup to be UD6.
Once the lookup dimension is added, I can use that dimension in my MD mapping as other source dimensions. I can even map that dimension and use in mapping scripts but it will not be exported to target application as it's used only in FDMEE.
Let's then change my MD definition to:
If Source Entity like West* And Source Product = "Comma_PDAs" And Source MyLookup = "NotForHFM"
Then Target Customer = "Francisco"
We edit the MD mapping:

Hey, hey! where is my lookup dimension? We didn't configure the lookup dimension in the Import Format so it will not be displayed :-(

We can define now our MD mapping and use the lookup dimension as source dimension:

The new condition is added to the SrcKey definition:

If we run the mapping process:

Using Special Characters in MD mappings
We can use asterisk special character (*) in both source and target value expressions.
Basics about using *:
- * > * (Ex: Acc1000 > Acc1000)
- Acc* > * (Ex: Acc1000 > 1000)
- Acc* > TAcc* (Ex: Acc1000 > TAcc1000)
- Acc* > *_200 (Ex: Acc1000 > 1000_200)
- ...
Above is what we all know for Like mappings.
There are some differences on how it behaves for MD mappings:

Basically * in the target represents the whole source:
- Case 1
- Source = Prefix*
- Target = *
- Result = Source = Prefix*
- Case 2
- Source = Prefix1*
- Target = Prefix2*
- Result = Prefix2Source = Prefix2Prefix1*
Let's give try in order to understand better?
I will first add suffix * to my target member (Francisco*)


So it seems that asterisk is applied to source dimension...
Let's then add a new condition to our MD mapping in order to add Source Customer as:

I would be expecting to be a customer now! but that would happen only with Like Mapping (No* > Francisco* implies NoCustomer > FranciscoCustomer) as you saw in previous table:

Note: it would be great to have a syntax so we derive the target member from different substrings of any source value. We could create a custom solution for that or maybe concatenate source dimensions and use new #FORMAT Mask mapping.
Sequence for MD mappings
I miss sequence map as it could be used in complex mapping logic but as you know it was removed in FDMEE. We now use rule names.
I always speak about two orders of precedence:
- Inter-order between mapping types: Explicit, In, Multi-Dimension, Between, and Like
- Intra-order between mapping rules of same mapping type: when mapping rules overlap within same mapping type, rules are processed in alphabetical order of the rule name (asc). It's a good practice to use numbers as prefix (10-xxx, 20-xxx)
Can MD mappings overlap?
Let's add a new mapping so condition for Entity is ENTITY=[WestS*]. We rename existing mapping to 10 and new mapping will be 20.
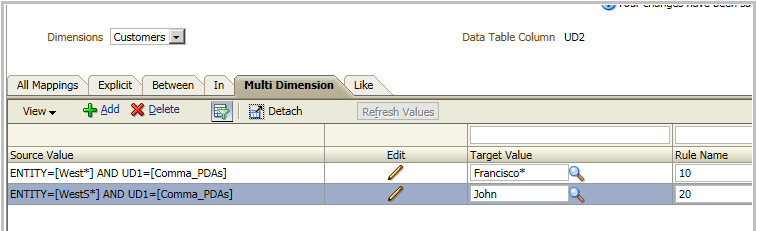
Which one will be executed?

What if we set rule name of the new mapping to 05?

05<10 (alphabetically) ... I'm now John!

It's now time to start working with rule names if you want to use sequence in mappings.
Note: be careful with alphabetical order: a < n but N < a, 5 > 10 but 05 < 10.
MD mappings in TDATAMAP Table
As other mapping types, MD mappings are stored in TDATAMAP (and other tables during mapping import and mapping processing like TDATAMAP_T and TDATAMAP_STG)
How are MD mappings stored?
Let's see our example:
If Source Entity like West* And Source Product = "Comma_PDAs"
Then Target Customer = "Francisco"

In the image above you can see how our GUI items (Source Value, Target Value...) are stored in TDATAMAP.
Is that all? No it is not. When we create/import a MD mapping, FDMEE creates additional rows in TDATAMAP. Which? It creates one row for each condition in the source value.
To see from a technical perspective, I would like you to pay attention to column DATAKEY. I'm going to run the following SQL query (you would need to adjust for your environment) in order to get related records to my MD mapping:

As you can see we have two additional records in TDATAMAP, one for each condition, and they relate to the MD mapping by having TARGKEY value as the DATAKEY value of the MD mapping.
This approach helps to create the SQL query that FDMEE runs for the MD mapping but it as also some drawbacks. The more MD mappings you have, the more records for conditions are created. When you reach a high volume of MD mappings, you may need to look at performance and analyze the need of additional indexes in FDMEE tables like TDATASEG_T or TDATAMAP. This is something you may need to take into consideration.
So I hope next time you query your TDATAMAP table you don't get surprised due to unexpected number of records per dimension :-)
When I understood how MD mappings were stored in the database I thought that having MD mappings using target column values instead of source column values might be an option.
I'm not going to detail any custom solution but I would like to share with you some ideas. I'm always fan of the statement "The more you know how the product works, the more creativeness you will have for your solutions".
I want to add a condition to my MD mapping so:
If Source Entity like West* And Source Product = "Comma_PDAs" And Target Account = "LaborCostAcc"
Then Target Customer = "Francisco"

Out of the box I cannot perform this with MD mapping (I could have #SCRIPT or #SQL mapping script instead)
But if we design a nice solution to update TDATAMAP so dimension name ACCOUNT is replaced by ACCOUNTX (Target Account Column in TADATASEG_T/TDATASEG)...

What would happen if we run the mapping process?

It seems data was mapped based on Source Entity, Source Product, and Target Account!
You don't believe, don't you? I wouldn't neither :-) but here you have the FDMEE process log. We can confirm how the SQL query has been generated by using ACCOUNTX instead of ACCOUNT:

Of course we would have to configure dimension sequence in target dimension details (Register > Target Application > Dimension Details) in order to ensure that Account is mapped before Customer dimension.
If we open the mapping to edit, you will see that condition for account dimension is not displayed correctly as we changed internally DIMNAME to ACCOUNTX and this value is not a valid one:

Please take into consideration that this custom solution is not 100% validated and of course it's not supported, so play this game at your own risk :-)
MD with multiple lines for same dimension
So far all logs I have shown in this post uses AND operator. The reason is that there was only one line per dimension. What about having the following condition?
Source Product = Comma_PDAs Or Source Product Like *Phones
When we add dimensions to the condition there is no impediment to add more than one condition to same dimension:

If we have a look to the syntax of MD we can see how OR operator is used for Product dimension:

The FDMEE process log will show the UPDATE statement as we expect:

MD mappings can be imported from text files or Excel files as other mapping types. The only difference is about syntax.

As you can see #MULTIDIM is used to define MD mappings.
In MapLoader, you will find instructions for MD mappings:

If you export mappings to Excel, bear in mind that you cannot import that Excel as it is only for mapping review. You will have to use MapLoader or txt/csv file instead:

Exporting mappings to Excel will produce an Excel file as follows:

OK, I think it's enough for MD mappings...
And remember, I haven't said MD mappings is your solution! As always, analyze requirements and design the solution which fits better for your business. Always try to find a solution balanced in performance and maintainability.
Enjoy!