
If you haven't done already you can visit the other two parts:
- Part 1: Introduction to UDA, initial ODI configuration
- Part 2: Configuring source system and source adapter in FDMEE
- Import Format: maps UDA columns to dimensions
- Location: data entry point
- Data Load Mappings: conversion rules for source data
- Data Load Rule: data extract definition
- Source Period Mappings: period filters for data extract
The import format is where we will link our source columns (imported from the source adapter page) with our HFM dimensions (including any potential lookup dimension defined in FDMEE)
As usual, we have to select the source system and the source adapter:

What can we select in the source columns?
We can select any column available in the UDA. In order to make column names understandable for anyone, the import format shows the "Display Name" property setup in the source adapter:

What can we select in the target dimensions?
By default you will see the list of dimensions of your target application including amount and lookup dimensions.In the case you need to concatenate multiple source columns into one target dimension you can add the target dimension again. Each source column assigned to the same target dimension will be concatenated using the concatenation character set in the import format definition:

I'm missing some things here:
- We cannot select Currency dimension (Oracle confirmed that will be available in PSU200)
- We cannot select description columns (DESC1 and DESC2)
- We cannot select Attribute columns
For description and attribute columns the only workaround is to adjust the ODI interface generated by FDMEE. However as I already explained in previous post, this change would have to be replicated in every environment as we won't be able to export and import the ODI objects.
Back to the import format configuration, we map source columns to target dimensions for each adapter:
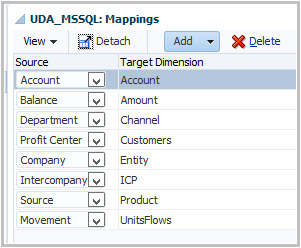








3. Data Load Mappings
I won't cover mappings in this topic. I just want to execute the DLR and see source data in FDMEE :-)










Customization of UDA
There are many scenarios where our source adapter needs to be customized. As opposed to the Open Interface Adapter, the ODI package and interface are generated from FDMEE. This has some drawbacks:
Migration to other environments
When we talk about migration, LCM has been enhanced a lot so most of the FDMEE artifacts can be migrated right now. But what about ODI objects?
UDA or OIA?
And the key question...now that I have the UDA, should I use OIA for my database integration?
My answer is that it depends on your requirements. In a straight forward integration you wouldn't need OIA. However, if you have a complex logic for data extracts, you may prefer OIA instead of UDA.
What could be enhanced?
Of course, as a new functionality, the Universal Data Adapter could be enhanced. From what I saw, it would be great if we had the following functionality besides the one I said above:
Back to the import format configuration, we map source columns to target dimensions for each adapter:
Regenerating the ODI Scenario
When we create new import formats or we change the columns map, we need to re-generate the ODI Scenario (FDMEE will execute this scenario when you click execute the DLR)

If everything runs fine we will get a success message. However this wouldn't be exciting so we got an error:

We troubleshoot the issue by starting with aif-WebApp.log:

I don't see any error except an issue with the interface but that could be normal because FDMEE just generates the ODI Scenario (it does not update the interface). And if you review the interface generated in the package, it doesn't have any reference to the source table (just variables and hard-coded values)
[2016-02-18T14:23:29.948-08:00] [ErpIntegrator0] [NOTIFICATION] [EPMFDM-140274] [oracle.apps.erpi.model] [tid: 22] [userId: <anonymous>] [ecid: 00iYe^P7VpJFw0zsRG007z2FtVU1zYIxL0000NS0000g1,0:1] [APP: AIF#11.1.2.0] [SRC_CLASS: com.hyperion.aif.odi.common.util.OdiConstants] [SRC_METHOD: logDebugInfo] Message - Issues: LKM is set for SourceSet or Staging Area but TargetDatastore column mappings do not reference any columns from a SourceDatastore of Dataset Default. Either delete SourceDatastore(s) or add source column references in one or more TargetDatastore column mappings for Dataset Default.
In fact, if I see the status icon I can see a green tick which means that the ODI scenario was successfully generated. We can even go to ODI and see it:

Weird. I saw this issue randomly happening in some projects so I decided to run the re-generate again. Now it worked. Don't ask me why, just be happy like me.

After re-generating the two ODI scenarios we are ready to create the other artifacts:

2. Locations
Nothing special to remark here, we just assign the import format as we don't have any other artifact (logic group, check group...)

3. Data Load Mappings
I won't cover mappings in this topic. I just want to execute the DLR and see source data in FDMEE :-)
4. Source Period Mappings
The source period mappings define the values for columns Period, Period Number, and Year. These values will be passed as parameters when we set our DLR with explicit period mapping type.
We can define multiple calendars and configure adjustment periods if needed.

Source period mapping are defined at source system level. Therefore if we have more than one table for the same source system and they use different calendar, we will have to configure multiple calendars. Calendars are then assigned to the data load rules as shown below.
Update (26/Feb/2016): If you have only one period column with alphanumeric values like JAN-16 you will need to enter those values in GL Period Column and classify that column as Period Class in the source adapter page. Then this column will be used as a filter when running the data load rule with explicit period type. Tested and working in a customer :-)
5. Data Load Rules
If you are familiar only with file-based loads you will see some differences in DLRs for the UDA:

We select the calendar defined for table SAMPLE_DATA and set period mapping type to Explicit.
We defined a parameter for the source adapter. This is used to filter data by column ERP_SOURCE. In order to show that works we have added a new line to the table with a different value than the value we want to extract data for:

Time to execute the DLR...3, 2, 1, go!
It's important to select a period or range of periods (UDA supports multi-period loads) with data in the table, or in other words, we have Period, Period_Number, and Year columns both correctly populated in the table and configured in the source period mappings.
Once is finished we navigate to Data Load Workbench and:

Voilà! our source data has been successfully imported and filtered.
Time to test the Oracle View. Will this also work like a charm?
For Oracle adapter, we defined a LIKE condition on column ERP_COMPANY:

Again we have added a new line to be filtered:

Running it...and no data imported!

What did I do wrong? Let's have a look to the FDMEE process log. I can see the SQL query executed. Actually I can't :-)
To troubleshoot source adapters you will have to visit ODI operator (either in ODI Studio or ODI console)

It seems that we forgot to add the % sign in the parameter value so new one value is BL% which will extract all data for companies starting with BL:

Let's execute it again:

Now it's time for you to explore other options.
There are many scenarios where our source adapter needs to be customized. As opposed to the Open Interface Adapter, the ODI package and interface are generated from FDMEE. This has some drawbacks:
- Any customization performed in the ODI objects will be deleted when we click on "Generate Template Package"
- Also, it will have to be replicated across environments
For reason I would prefer to customize on the source side. For example, if we need to join two tables, we could create a SQL view instead of using tables as a source.
At the moment, I can only think about customizing the interface in order to import data for descriptions and attribute columns but this is something that Oracle will probably fix so I wouldn't worry.
At the moment, I can only think about customizing the interface in order to import data for descriptions and attribute columns but this is something that Oracle will probably fix so I wouldn't worry.
Migration to other environments
When we talk about migration, LCM has been enhanced a lot so most of the FDMEE artifacts can be migrated right now. But what about ODI objects?
- Topology: the topology needs to be re-created manually in the target environment
- Designer Objects: the packages/interfaces/scenarios need to be re-created from FDMEE in the target environment once LCM migration is done.
Why? basically, as already said, due to ODI master and work repositories having the same internal id across environments.
Hopefully in the future, Oracle adds a button "Generate all ODI objects" :-)
UDA or OIA?
And the key question...now that I have the UDA, should I use OIA for my database integration?
My answer is that it depends on your requirements. In a straight forward integration you wouldn't need OIA. However, if you have a complex logic for data extracts, you may prefer OIA instead of UDA.
What could be enhanced?
Of course, as a new functionality, the Universal Data Adapter could be enhanced. From what I saw, it would be great if we had the following functionality besides the one I said above:
- Filtering capabilities. For example, we can't add a filter to extract data having a column value different than the parameter we passed. Also we cannot add complex nested filter conditions.
- We cannot select import mode. It is always imported in replace mode.
- We cannot use import scripts. If we need any import operation on source fields that would need to be done in a SQL view.
- Being able to apply SQL functions on source fields. These functions would be available in the import format as expressions.
Can you think in any others? I'm sure so feel free to add your comments!
With this post I'm done with discovering the new Universal Data Adapter. At least until I find something interesting to show ;-)
Update 22/4/2016: it seems that table/view names must be in upper case. Otherwise the table import definition fails.
Update 22/4/2016: it seems that table/view names must be in upper case. Otherwise the table import definition fails.
Enjoy!
Thanks Francisco Amores!!
ReplyDeleteIts worth following your posts. Everything works fine, except one thing. During the Export to planning (multi-currency), I was nowhere able to to map Currency anywhere in the integration. Due to which data load completes successfully but no data will be there in the target Planning application.
Can you please advice, if you have faced similar situation.
Thanks again..:)
Hi,
DeleteOracle confirmed this is a bug which will be fixed in next version of UDA.
In the meantime there are some workarounds. You can create a lookup dimension for Currency and import your currency column into data. Then you can map your lookup dim and update CURKEY column in TDATASEG in the event script AftProcMap.
This comment has been removed by the author.
DeleteThank you so much, was able to complete the requirement based on your expert comments..:)
DeleteHi Franc,
ReplyDeleteAll you have done is for only Single Period tables. How do we handle Multi Period Source tables (Jan to Dec) in single row data.
Regards,
Ravi
Thank you very much. I'm new to FDMEE and I'm learning a lot for your posts. One question I have, though, is can I use the UDA to bring in Data Load maps? I've been researching this, but I can't fin a yes or no, and if yes, and example.
ReplyDeleteHi,
Deletesorry for late response
no you can't
Very informative blog. Thanks for posting.
ReplyDeleteI have a question regarding how to use the universal adapter with a table with multiple rows of data. It does not seem possible to configure the universal adapter to bring data from a table that has the monthly data in different columns of the same row.
Is there something I am missing?
Thanks
Marco A.
Hi,
Deletesorry for late response
Not in easy way. Better use OIA if you have that requirement
Very informative blog. Thanks for posting.
ReplyDeleteI have a question regarding how to use the universal adapter with a table with multiple rows of data. It does not seem possible to configure the universal adapter to bring data from a table that has the monthly data in different columns of the same row.
Is there something I am missing?
Thanks
Marco A.
I have the similar question? did you find any solution for the same?
DeleteDear Francisco Amores,
ReplyDeleteThanks you soo much for providing valuable information to us. I need your help here. Currently we are using UDA for integrating with EBS view. But I am experiencing problem with Source period mapping. If the EBS view contains multiple periods of data but I wanted to load the data only for one period. So I have added that period information in source period mappings. But the issue is it retrieving the data from any period and pushing to target period.
Eg1: In EBS View has the data for Jan-17 to Dec-17. In this case I wanted to load the data only for Jan-17. Is it possible through UDA?
Please add your comments/suggestions.
Thanks your help in Advance
Kumar...
Hi Kumar,
Deleteyes that's possible. You need to classify the period column as Period. Then in you source period maps, make sure that you have the same values as the View.
Also, make sure that you execute the DLR with Explicit period mappings.
Cheers